供應長期0優質USB母座沉板刺破式不卷邊連接器,穩固連接解決方案

在電子元器件領域,連接器的質量與性能直接關系到整個電子產品的穩定性和可靠性。供應長期0優質USB母座沉板刺破式不卷邊連接器,正是針對高標準連接需求而設計的一款卓越產品。它結合了沉板安裝、刺破式端接和不卷邊工藝等多項技術優勢,為各類電子設備提供了高效、穩固且耐用的連接解決方案。
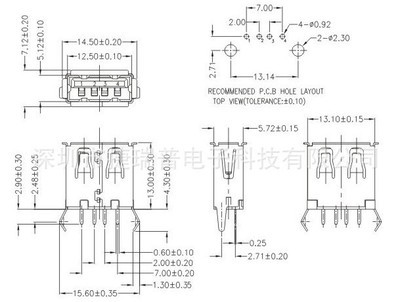
沉板式設計是這款USB母座連接器的一大亮點。這種設計使得連接器在安裝時可以嵌入印刷電路板(PCB)中,從而降低整體組裝高度。這對于追求輕薄化、緊湊化的現代電子設備(如超薄筆記本電腦、平板電腦、便攜式醫療設備等)而言至關重要。沉板安裝不僅節省了內部空間,還有助于提升產品結構的整體性和美觀度。
刺破式(或稱為絕緣位移接觸IDC)端接技術,革新了傳統的焊接連接方式。在組裝時,連接器的鋒利觸點可以直接刺破電纜的絕緣層,與內部的導體建立電氣連接。這種方式省略了剝線、上錫和焊接等多道工序,顯著提高了生產效率和組裝一致性,同時減少了因手工焊接帶來的潛在質量風險,如虛焊、冷焊或熱損傷。它尤其適用于自動化大規模生產,能有效降低制造成本并保證連接性能的均一穩定。
“不卷邊”工藝則進一步提升了連接器的機械強度和耐久性。通常,連接器的金屬外殼邊緣在成型后可能需要進行卷邊處理以消除毛刺或增強結構。而不卷邊設計通常意味著采用了更高精度的模具和沖壓工藝,使得外殼邊緣光滑平整、結構一體性更強。這不僅提高了連接器本身的抗沖擊和抗變形能力,也在多次插拔使用中能更好地保護內部端子,減少因外殼變形導致的接觸不良,從而延長了連接器的使用壽命。
這款長期穩定供應的0優質USB母座連接器,以其沉板、刺破式和不卷邊的綜合特性,在電子元器件市場中脫穎而出。它確保了信號傳輸的可靠性,適應了高密度集成的PCB設計,并滿足了高效自動化生產的需求。無論是用于消費電子產品、工業控制設備還是通訊裝置,它都是一個值得信賴的優質連接選擇。在世界工廠網中國產品信息庫中,此類高性能連接器為制造商和研發人員提供了豐富的元器件資源,助力他們打造出更具競爭力的電子產品。
如若轉載,請注明出處:http://www.wn799.cn/product/26.html
更新時間:2026-05-16 21:49:01